
The other evening a bunch of us were sitting in a friend's living room while a series of photos scrolled across her TV. The photos were a screen saver served up by her new Apple TV box. Some of the pictures were of people, birds, flowers, cats and other typical stuff. But in the mix were also shots of price tags, bar codes, bags of mulch and other stuff she had thought about buying at some point.
“What are those doing there?” somebody asked.
“I don't know”, she said. “I thought I threw those away.”
“That's scary”, somebody said. “What if some of your shots were nude selfies, or porn?”
“I don't have that”, she replied. “But I don't like not knowing why shots I never intended to share are showing up on my TV.”
Even though most people in the room were Apple customers, and some knew a bit about Apple TV, the room itself had no clear sense about how Apple TV decides what photos to show, or whether the photos on the screen come from the user's phone, laptop or iCloud (the non-place where Apple may or may not store some or all of what customers shoot with their cameras or phones). So finally, a rough agreement emerged out of collective un-knowing.
“It's probably the cloud”, somebody said.
“Yeah, the damn cloud”, another agreed. What else to blame than the most vague thing they all knew?
Then my wife said something that knocked me over.
“The cloud has boundary issues.”
Her point was about the psychology of the cloud, not its technology. In psychology, boundary issues show up when one person doesn't respect the boundaries set by another. And in today's networked world, personal boundaries are ignored as a matter of course, mostly because people don't have ways to set them.
In pre-Internet days, personal computers came with their own built-in boundaries. Even when they were connected to shared printers and filesystems, it was clear where the personal stuff ended and the shared stuff began.
In today's networked world, smart geeks mostly still know where local stuff ends and remote (cloud-located) stuff begins—or at least where the logical boundaries are. But for most of the rest of us, most of the time, the cloud is a hazy thing. And that haze has been troubling us ever since we chose “the cloud” over better terms that would have made more sense. (Such as calling it a “utility”, which Nicholas Carr suggested in his 2010 book The Big Switch.)
According to Google's Ngram Viewer, mentions of “cloud computing” in books hockey-sticked in 2004 and continued to rise after that Usage of “the cloud” also rose over the same period. According to Google Trends, which looks at search terms, “the cloud” hockey-sticked in 2011 and flattened after that, because its usage became ubiquitous.
William F. Buckley, Jr., once said his purpose in life was “to stand athwart history, yelling 'stop'”. In a similar way, Richard M. Stallman stood athwart history when, in September 2008, he called the cloud “worse than stupidity: it's a marketing hype campaign”. “In What Does That Server Really Serve?”, published in March 2010, RMS wrote:
The information technology industry discourages users from considering ... distinctions. That's what the buzzword “cloud computing” is for. This term is so nebulous that it could refer to almost any use of the Internet. It includes SaaS, and it includes nearly everything else. The term only lends itself to uselessly broad statements.
The real meaning of “cloud computing” is to suggest a devil-may-care approach towards your computing. It says, “Don't ask questions, just trust every business without hesitation. Don't worry about who controls your computing or who holds your data. Don't check for a hook hidden inside our service before you swallow it.” In other words, “Think like a sucker.” I prefer to avoid the term.
About SaaS (Software as a Service), he adds:
These servers wrest control from the users even more inexorably than does proprietary software. With proprietary software, users typically get an executable file, but not the source code. That makes it hard for programmers to study the code that is running, so it's hard to determine what the program really does, and hard to change it.
With SaaS, the users do not have even the executable file: it is on the server, where the users can't see or touch it. Thus it is impossible for them to ascertain what it really does, and impossible to change it.
Furthermore, SaaS automatically leads to harmful consequences equivalent to the malicious features of certain proprietary software. For instance, some proprietary programs are “spyware”: the program sends data about users' computing activities to the program's owner....
SaaS gives the same results as spyware because it requires users to send their data to the server. The server operator gets all the data with no special effort, by the nature of SaaS.
And, sure enough, spying on individuals by commercial entities is now so normal and widespread that most of us living in the networked world can hardly tell when it's not happening. This is why ad and tracking blockers have become so popular, and why survey after survey shows that more than 90% of people are concerned about privacy on-line.
But spying is just the symptom. The deeper issue is boundaries. In the networked world we don't have them, and because of that, others take advantage of us.
“Give me a place to stand and I can move the world”, Archimedes said. Note that he didn't say, “Give a lot of people a place to stand.” He meant himself. And his point applies to personal boundaries as well. Each of us needs to set our own. That's our fulcrum.
Free software provides a good model for approaching this problem, because its framing is personal:
“Free software” means software that respects users' freedom and community. Roughly, it means that the users have the freedom to run, copy, distribute, study, change and improve the software. Thus, “free software” is a matter of liberty, not price....We campaign for these freedoms because everyone deserves them.
Most of us don't write software, but all of us create and use data. We also have containers for data in our computers. We call those containers files, which live in directories, which are visualized as folders in graphical user interfaces.
As a mental concept, containers could hardly be more important. In “The Metaphorical Structure of the Human Conceptual System”, George Lakoff and Mark Johnson say, “the nature of the human conceptual system...is fundamentally metaphorical in character” and involves “ontological concepts arising in physical experience, among which is the container”. They provide examples:
When you have a good idea, try to capture it immediately in words. Try to pack more thought into fewer words. His words carry little meaning. Your words seem hollow. The ideas are buried in terribly dense paragraphs. I can't get the tune out of my mind. He's empty-headed. His brain is packed with interesting ideas. Do I have to pound these statistics into your head? I need to clear my head.
All those statements presume containers: spaces with boundaries. We have those with files, directories, folders, drives and storage systems. We don't with clouds, beyond knowing that something resides “in the cloud”. We also don't with cookies and tracking beacons that get injected (from clouds) into who knows where inside our computers and mobile devices.
In the absence of boundaries we set, controlling entities (such as Amazon, Apple, Facebook and Google) assume that boundary-setting is their job and not ours, because so much of the world's work can only be done by big systems that enjoy degrees of “scale” not available to individual human beings.
Yet personal freedom has scale too, if it is grounded in our nature as sovereign and independent human beings. This is why free software was such a powerful idea in the first place, and why it remains the world's most rigorous guide for software development. We may not always obey it, but we always know it's there, and why it is valuable.
While free software respects code and what can be done with it, we need a similar set of guiding principles that respect personal data and what can be done with that. I believe these should be terms that we assert, and to which others can agree, preferably automatically.
In fact, there is a lot of work going on right now around personal terms. I am involved with some of it myself, through Customer Commons. Figure 1 shows one straw-man example of terms, drawn up by Mary Hodder at the 19th Internet Identity Workshop (IIW) last year.
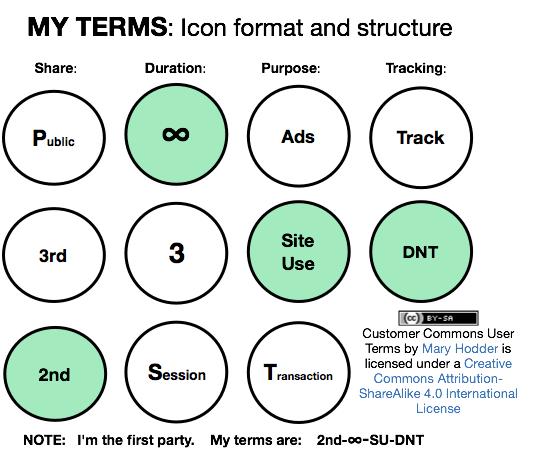
Figure 1. User Terms (from Mary Hodder at the 19th Internet Identity Workshop)
Terms and privacy policies (that we assert, as individuals) will also be on the table at two events this month.
The first is the 21st IIW, which takes place twice per year at the Computer History Museum, in the heart of Silicon Valley. It's a three-day unconference, with no keynotes and no panels—just breakouts on topics of the participants' choosing. It costs money, but it's cheap compared to most other conferences, and it's far more intense and productive than any other conference I know. The dates are October 27–29, 2015. Register here: iiwxxi-21.eventbrite.com.
The second is VRM Day, which happens on October 26, 2015, the day before IIW, in the same location. The purpose is to discuss VRM (Vendor Relationship Management) development, which is all about freedom and independence for individuals in the commercial world. It's free, and you can register here: vrmday2015b.eventbrite.com.
See you there.
