
How to federate CLucene personal document indexes with PostgreSQL/TSearch2.
The libferris project has two major goals: mounting anything as a filesystem and providing index and search for anything it can mount. Using libferris to provide desktop search was described in my February 2005 article, “Filesystem Indexing with libferris” in Linux Journal. The indexing capabilities of libferris have grown since then. One new feature is to allow a group of indexes to function logically as a single, “federated” index. This lets you have an index for your file server, another for your man pages and a third for your personal documents. You then can run queries against all three as though they were a single index.
libferris handles its index and search using a plugin system. There currently are index plugins for db4, PostgreSQL, ODBC, Redland (RDF), Xapian, Beagle, Yahoo, LDAP, CLucene, Lucene and external processes. The indexes that form a federated index in libferris can use any mixture of those index plugins.
libferris has two different types of indexing plugins: full text and metadata. The metadata interface of libferris is based on the Extended Attribute (EA) kernel interface. Having two index plugin types allows the index plugin to organize data on disk to best support queries.
A full-text index normally will maintain for each word from a human language a list of which files contain that word and a statistical measure of how important that word seems to the document. The statistic allows documents that are “more relevant” to be presented first in the results. Such statistics normally relate to how large a file is, how often the word appears in that file and how rare the occurrence of that word is across all indexed files.
A metadata index has to associate a docid with a keyword and value. For example, /tmp/foo has a size of 145. The metadata index has to be able to process queries, such as size>=4kb && modified this week, and efficiently return the docids for files that satisfy this query. The main difference between metadata and full-text index plugins is that the metadata queries contain value comparisons on metadata (for example, mtime>=last week), whereas full-text queries generally are more interested in the presence of a word in a file.
From an index user's point of view, having this distinction is an annoying implementation artifact. To get around this, a full-text index can be linked to a metadata index using the feaindex-attach-fulltext-index command. Queries combining both metadata and full-text searching can then be executed on the metadata index. It is convenient to think of the metadata index as owning the full-text index.
The metadata query format reserves any metadata names starting with ferris- to have special meaning. A metadata name ferris-fulltext-query or ferris-ftx will execute its query value as a full-text query on the linked full-text index. Shown in Listing 1 is a metadata query seeking all files under a given size with the two given words in them. If instead of combining the results with &, we used the or operator | in the query, any results matching either subquery would be returned. To query a full-text index, the findexquery command is used. Combined metadata and full-text indexes are queried using the metadata query command feaindexquery.
The above discussion of docids becomes relevant when combining two types of index plugins like this. The greatest efficiency can be gained when both the metadata and full-text index plugins are using the same storage—for example, the PostgreSQL (metadata) and TSearch2 (full-text) plugins using the same underlying PostgreSQL database, or both indexes using the same CLucene storage.
The efficiency is obtained because each URL has the same docid. Using the PostgreSQL combination as an example, to resolve the query from Listing 1, the full-text subquery will be run against the TSearch2 plugin obtaining a set of matching docids. The set of docids matching the size query is obtained, and the set intersection of the size and full-text query results is returned. This final step can be done only if it is known that both the metadata and full-text index have the same docid for the same URL. Otherwise, the docids from the full-text query have to be converted into URL strings and then into the docids of the metadata index first.
When using a metadata and full-text plugin together like this, make sure that each file is added to both indexes.
Each metadata index plugin will automatically detect if it is safe to use the docids of the full-text index directly that is linked to it.
The federation index plugin is a metadata plugin. A federation is formed using many metadata indexes with one nominated as the writable index. As each metadata index can own a full-text index, this allows federations of an arbitrary number of full-text and metadata indexes. Each index in the federation can be updated independently of the federation.
Indexes are created using either the fcreate or gfcreate tools. The former is a command-line tool, and the latter has a GTK+ 2 GUI. In this article, I use the fcreate command. To find out what other options are available during index creation, simply replace fcreate with gfcreate, and a GUI will be presented. Both metadata and full-text indexes reside in a directory, even if only configuration settings are saved in that directory. For example, using the PostgreSQL plugin, the indexed data will be in a PostgreSQL database and only a small config file will live in the filesystem directory. Using directories like this allows you to tell libferris which index to use by passing a filesystem path.
Some shell scripts are distributed with libferris to help set up indexing. For PostgreSQL and CLucene, these scripts start with ferris-recreate-primary-fulltext-and-eaindex-as and end with either clucene or postgresql. Both are geared to set up your default metadata and full-text indexes using the nominated index plugin. Your default indexes are stored in subdirectories of ~/.ferris.
We'll make our default index a federation of a local CLucene index for personal files and PostgreSQL for a file server. This means we will have five indexes in total: the federate metadata index, a metadata and full-text CLucene index, and a metadata and full-text PostgreSQL index.
The two CLucene indexes will be linked together, and the two PostgreSQL indexes will be linked to each other. We can use the default path in ~/.ferris for the federation index. We will put the CLucene indexes in ~/clucene-index. I'll assume the machine that will run PostgreSQL and maintain the file server index is a server called fshost. The index can be on a different machine from the actual file server if desired. The contents of many file server machines and other documents can be added to the file server index if you like.
For PostgreSQL indexes, the directory for the index will have only a configuration file in it. This file will contain information telling the index plugin where the database is located and what user name and password to use to connect. I'll assume we are creating the PostgreSQL file server indexes in /ferris-index on the file server, though any path is fine. To make things simple for people who are intended to use this index, having its directory on the file server makes its use in a federation simple. We'll use the PostgreSQL database name ferrisindex. The setup is shown in Figure 1.
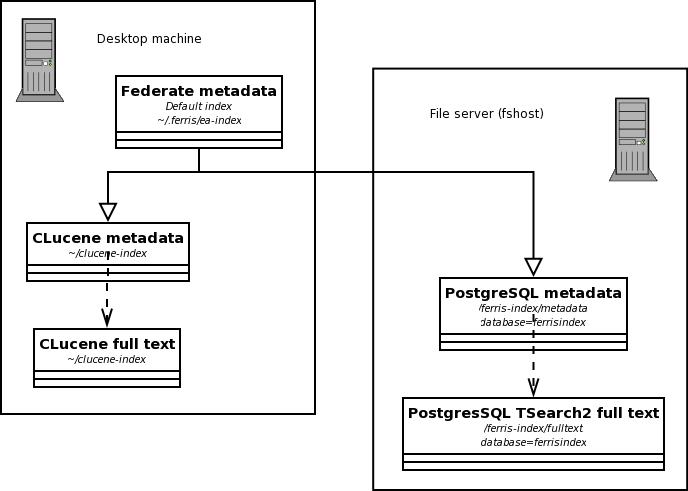
Figure 1. The Federation of Indexes
To use CLucene for local indexing, we can use the clucene recreate script with a minor modification for the index paths, as shown in Listing 2. Notice that the second fcreate has the db-exists=1 parameter to tell the index plugin that there is an existing CLucene index at this path. This places both metadata and full-text information into the same CLucene index.
Make sure that metadata you want to use in queries is not listed in attributes-not-to-index and will not match attributes-not-to-index-regex for the index. Run gfcreate /tmp --create-type=eaindexclucene to find your current default values for these parameters.
Setting up a PostgreSQL/TSeach2 combination is a two-step process. The first step, using the ferris-setup-template-findex-database.sh script, creates some template databases and needs to be done only once. The script assumes it is being run on the host that has the PostgreSQL database on it. This script installs Generalized Index Search Trees, TSearch2 and PL/pgSQL into two template databases that the metadata and full-text plugins take advantage of. Some of these features live in a postgresql-contrib package in many distributions.
The commands shown in Listing 3 create a TSearch2 full-text index and a metadata index in the same database on host fshost. These will reside in /ferris-index as mentioned before. This directory should be readable over the network by those who are intended to use the index. Below, I assume this is exported using NFS and access the path using fshost:/ferris-index. These indexes are then linked together to allow combined queries. Make sure that the db files in /ferris-index are readable by those who should be able to access this index.
Back on the desktop machine, we then create a federated index combining the local CLucene and remote PostgreSQL indexes, as shown in Listing 4.
This assumes that the parameters used to create the PostgreSQL indexes are valid for the desktop user. As libferris knows how to mount db4 files, changes to the configuration settings can be done with libferris clients. See Listing 5, which uses the ferris-redirect command to allow shell redirection into any libferris file.
The federation index plugin delegates all of its work to other existing indexes. Because of this, we nominate that when files are added to the federate index, then the federate plugin should delegate the add to the CLucene plugin maintaining our personal index.
Most index plugins will detect whether a file has not changed since it was indexed and automatically skip it upon re-indexing. At least the Xapian, Redland, CLucene and PostgreSQL plugins support this. Those plugins that do not currently support this will issue a warning. This allows a cron job simply to run find to list files that should be in the index and pipe them to feaindexadd.
Shown in Listing 6 are commands to populate both indexes. Note that when using CLucene for both full-text and metadata indexes in a shared database, you have to add files to the full-text index first. This limitation is due to the CLucene API.
We now have the choice of looking in our personal files, the file server or both with our queries. The query syntax is identical for all three; we need to specify only which index to use. If we don't specify an index, we use the default, which on our desktop machine is our federation. Shown in Listing 7 are a few example queries. The =~ operator in the last example is a regular-expression match.
libferris can present the result of a query as a filesystem. This can provide a quick interface for clients on the network to query the file server. The ferrisls command can output its results as an XML file. Given a Web form and your favourite Web scripting language, queries can be run with ferrisls, and the resulting XML file XSL translated into nice HTML for the client.
The FUSE module also allows access to search results directly through the kernel ready for exporting to the network.
The eaq:// virtual filesystem takes a query as a directory name and will populate the virtual directory with files matching the query. Other closely related query filesystems are the eaquery:// tree. The eaquery:// filesystem has slightly longer URLs, but it allows you to set limits on the number of results returned and to set how conflicting filenames are resolved. Some example queries are shown in Listing 8. Normally, a file's URL is used as its filename for eaquery:// filesystems. The shortnames option uses only the file's name, and when two results from different directories happen to have the exact same filename, it appends a unique number to one of the result's filenames. This is likely to happen for common file names, such as README.
The default federation plugin assumes that for any file the same URL is used to access it from all indexes in the federation. For example, consider a file with URL file://doc/lj.txt on the file server. If this file is returned as a match to a federated query, the person performing the search will want to find the file at file://doc/lj.txt relative to his or her local machine. If the /doc directory is exported as an NFS share for desktop machines, it should be mounted as /doc on the clients.
If paths between the file server and clients differ, URL modification can be done by the federation plugin. The supported URL modification will be familiar to Perl users. For each index in the federation, a regex and format string can be provided to rewrite URLs returned from that index. URL rewriting is shown in Listing 9. This example will alter any files from /tmp on the file server to be mytmp on the desktop machine.
In order to determine if a document has not changed since it was indexed, the PostgreSQL index plugins load some information from the database into a RAM cache. If more than one process is updating a PostgreSQL index, more work may be done than is strictly necessary. The PostgreSQL index plugins are safe to be updating the index while clients are performing queries. Many of the other plugins provide only the level of concurrent access that the underlying index library offers. This usually amounts to many index readers or one exclusive writer.
There are Xapian index plugins for both metadata and full-text indexes. Unfortunately, Xapian has limited support for metadata queries, mainly equality only. For a metadata and full-text combination, using Xapian for both, files must be added to the metadata index first and then the full-text index.
The CLucene plugins are much easier to use than the Lucene ones. The latter relies on GCJ and an install of Lucene that GCJ can compile C++ code against.
Additional effort is required to use the PostgreSQL index plugin for a file server index that supports emblem and geospatial queries.
Resources for this article: /article/9390.
