
CD-ROM content needs a search engine that can run in any browser, straight from static index files. JavaScript and XML make it possible.
I recently was working on a CD-ROM catalog for a client, and he requested that it have keyword search ability. My searches for solutions to such a request kept turning up proprietary OS software that required an install on the user's machine and a license fee paid per copy distributed. Such installation requirements are limiting and would cost a lot over time. Furthermore, all of the CD-ROM users were not going to be using a single proprietary OS, so this automatically reduced the potential customer base. While sitting back to think about the situation, a package in my mailbox caught my eye—the Linux Journal Archive CD. I figured if anybody had solved this problem, it was sure to be on the LJ Archive. Imagine my disappointment upon discovering that the LJ Archive CD has a really good index but no search engine. If a solution was to be found, I would have to find it myself. This article is about scratching that proverbial itch with jsFind.
One of my earliest considerations was how to distribute and license my solution, jsFind. I showed early versions of it to colleagues, and they felt I should follow the model in which I license the code and then market it. jsFind then would be using the same model as other competing search engines for this type of content. Personally, I would rather spend my time coding than marketing, and I suspect the total market is not very large. I would rather get informative CD-ROMs and be able to search them easily using any browser and platform I choose.
The GNU Public License (GPL) was more in line with my goals. By freely distributing jsFind, it would be marketed based on its own merits, gaining improvements and contributions as it grows. At the risk of preaching to the choir, one of the goals of proprietary systems is to lock users in to being required to use their system by every possible means. For example, when one gets a CD-ROM and is required to use a specific browser and a specific OS to use the search engine, then that user is forced to access a copy of that OS. CD-ROM producers also are forced to keep buying development tools for that OS in order to stay current. The result is consumers and producers are locked in to the proprietary OS vendor. Releasing jsFind under the GPL would break the cycle.
The jsFind keyword search engine itself is a small JavaScript program of about 500 lines. A browser that supports DOM Level 3 JavaScript extensions can load XML files. The current versions of Mozilla, Netscape and Microsoft Internet Explorer all support these extensions, and the upcoming release of Konqueror will do so as well. The index is stored as a set of XML files, and the JavaScript searches through these in an efficient manner to generate results of a keyword search. These results then can be posted back to the Web page that requested them, also using JavaScript.
One of the key dependencies of jsFind is that a CD-ROM be a set of static information. Unlike Web search engines or any other dynamic data set, once pressed, a CD-ROM isn't going to change. SWISH-E is better suited for dynamic indexing, especially when one has the luxury of configuring a server to do the keyword searches. Therefore, jsFind is based on the idea that the only thing available is a standard Web browser with JavaScript and a set of browseable files—a severe restriction on possible solutions.
Most indexing method algorithms try to strike a balance between insert, update, delete and select times. Because a CD-ROM is static, there will never be a delete or update. Insert takes place prior to CD burning and can be quite time consuming. Select time is critical for user responsiveness. An additional constraint of small space is required, because a typical CD-ROM can't hold more than 700MB.
Re-examining indexing methods based on these constraints yielded an interesting solution: B-trees and hashes are the two most commonly used indexing methods. I chose to use B-trees due to the fact that a filesystem organizes files in a tree; this could be used to store the structure of the B-tree, saving some precious space in the process. Second, the key/link pairs could be analyzed, and a balanced B-tree could be created. The structure of the XML files themselves was kept as minimal as possible, so single-letter tags were used as a space-saving move.
A B-tree is a data structure used frequently in database indexing and storage routines. It offers efficient search times, and storage/retrieval is done in blocks that works well with current hardware. A B-tree consists of nodes (or blocks) that have an ordered list of keys. Each key references an associated data set. If a requested key falls between two keys in the ordering, a reference is provided to another node of keys. A balanced B-tree is one in which the maximum number of nodes that could be loaded on a search stays at a minimum.
jsFind creates a B-tree by using XML files for the nodes of the tree, and the directories on the filesystem correspond to references to another set of nodes. This allows for part of the structure of the B-tree to be encoded on the filesystem. If all the XML files are in the same directory, file open times might become long, so using the filesystem efficiently requires subdirectories.
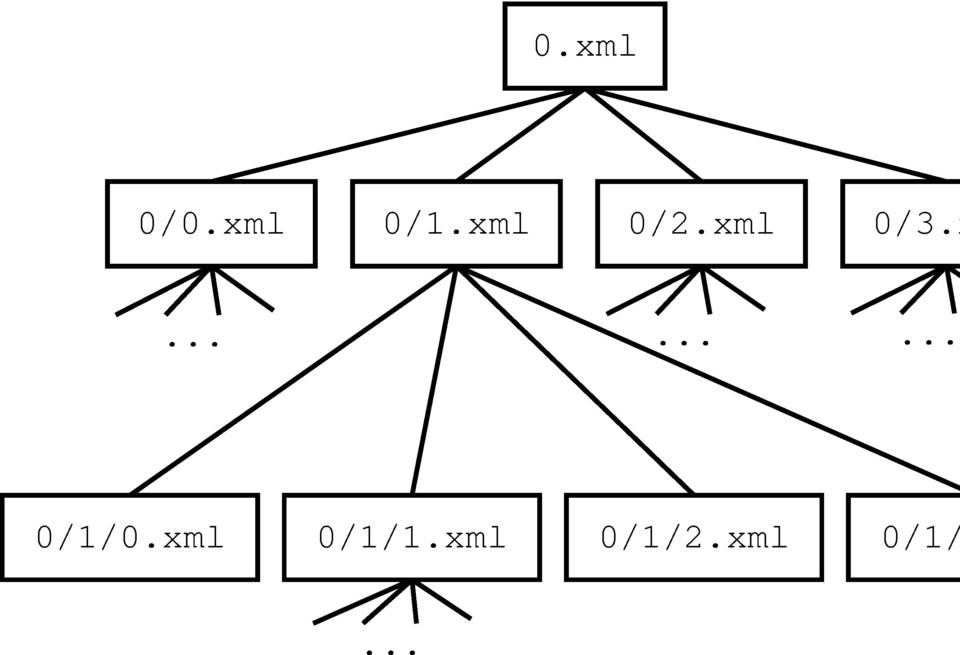
Figure 1. jsFind creates a B-tree, where an XML file represents each node.
End users need not worry about any of this. They simply can type words to search for on a Web page, and jsFind returns links to pages containing those keywords. No install, no worries, just a seamless experience.
Figure 2. Example Search Results
As a developer of content, however, your life is not so simple. The jsFind toolset tries to make your job as easy as possible, though. To start, you need Perl and a fair amount of CPU time to generate the index. Most likely you also need a copy of all the target browsers so you can test the results. An example with a Makefile can be found in the jsFind distribution, but several steps need to be tailored to your individual needs.
The first step is to get a data set consisting of keywords and links; the input format needs to be XML. I used SWISH-E with a custom patch to extract and create an index and then exported the results to the XML format suitable for processing with jsFind's Perl scripts. Assuming the SWISH-E index is in the file mystuff.index, the following command exports the file to XML:
$ swish-e -f mystuff.index -T INDEX_XML > mystuff.xml
The structure of this XML file is as follows:
<index>
<word>
<name>akeywordhere</name>
<path freq="11" title="Something neat">
/cdrom/blah.html
</path>
<path freq="10" title="More cool stuff">
/cdrom/blah2.html
</path>
</word>
<word>
...
</index>
The XML file is sorted by order of keyword name.
The resulting data set still is probably too large, because SWISH-E doesn't concern itself with filtering out words like “and”, “this” and other common English words. Two Perl programs can be used to filter the result, occurrences.pl and filter.pl. occurrences.pl creates a list of keywords and determines the number of times they occur in an index:
$ occurrences.pl mystuff.xml | sort -n -k 2 \ > mystuff.keys
This file has a keyword on each line followed by the number of occurrences:
$ tail mystuff.keys you 134910 for 138811 i 149471 in 168657 is 179815 of 252424 and 273283 a 299319 to 349069 the 646262
At this point, the mind-numbing task of creating a keyword exclusion file is performed. Edit the key file and leave in all the words that should be excluded from the final index. Even better than creating your own file, get a copy of the 300 most common words in English from ZingMan at www.zingman.com/commonWords.html.
Next, run the filter. The Perl script filter.pl included in this package filters a result set. It currently is set to exclude any single-character index keys (except the letter C), any key that starts with two numeric digits (so things like 3com and 0xe3 are okay) and anything in the specified exclusion file:
$ filter.pl mystuff.xml mystuff.keys > \ mystuff-filtered.xml
This step takes quite a bit of time. Make sure the final size of the file falls within the limits of the space available. The final index should be about 75% of the size of the filtered index. If it's too big, whittle it down to size with a longer keyword exclusion file.
The second big step is creating the index itself. A script is provided to break this index down into a set of B-tree XML files:
$ mkindex.pl mystuff-filtered.xml 25 blocksize: 20 keycount: 101958 depth: 4 blockcount: 5098 maximum keys: 194480 fill ratio: 0.524259563965446 bottom fill: 92698 Working: 11%
Parameters are the next thing to consider. The blockcount states how many B-tree blocks need to be created. Each block creates one key nodes file and one data nodes file, and one directory. If the total number of files and directories is too high, increase the blocksize until it fits. The depth shows the number of levels in the tree. If the blocksize gets too large, search times slow down, so bottom fill is how it is kept balanced. Once that number of keys is put in the bottom row, the bottom row is closed to further node creation, thus creating a balanced tree.
If all works well, you should end up with three files in the current directory: 0.xml, _0.xml and the directory 0. These are the index files. The next step is to follow the provided example for integrating the results into your HTML/JavaScript. The results then are passed to a provided routine and need to be posted back to the current Web page. The example does this using JavaScript to create dynamic HTML.
Many improvements to jsFind are possible, and they'll come as it is used by open-source users. Such features as having an image archive search with thumbnails, multipage result sets and stronger browser compatibility checks all are possible using this code as a springboard.
The 2002 LJ Archive CD-ROM contains the jsFind search engine. If you're a developer of CD-ROM content, please consider using jsFind over solutions with proprietary OSes. Doing so will be cheaper and will connect you with a larger potential user base. As an end user, I hope to be delivered from having to install a program and dual-boot simply to search content on a CD-ROM. Other innovative uses for the software might be possible as well, so consider it to be one more tool in the open-source toolbox.
